
连接数据库
数据库连接
1
mysql -h $host -u $username -p
设置用户密码
1
mysqladmin -u $username password $password
修改用户密码
1
mysqladmin -u $username -p password $new_password
用户管理
创建用户
1
create user $username@$ip identified by '$password';
用户名@ip的作用是限定用户在哪些ip下可以访问数据库,如:ejin@192.168.1.1. 表示ejin只有在192.168.1.1的ip下才能访问到数据库。ejin@192.168.1.%. 表示ejin能在192.168.1.*这个ip段下访问数据库。ejin@%. 表示ejin能在任意ip下访问数据库。
删除用户
1
drop user $username@$ip;
修改用户
1
rename user $username@$ip to $new_username@$ip;
修改密码
1
set password for $username@$ip = Password('$new_password')
查看用户权限
1
show grants for $username@$ip;
授权
1
grant $privileges on $db_name.$table_name to $username@$ip;
$privileges的权限有:- select
- insert
- create
- drop
- update
- create
- all privileges
- …
同时授权多个,用逗号分隔,如:
select,insert。取消授权
1
revoke $privileges on $db_name.$table_name from $username@$ip;
数据库操作
显示所有的数据库
1
show databases;创建数据库
1
create database $db_name default charset utf8 collate utf8_genral_ci;
打开数据库
1
use $db_name;
数据表操作
显示数据表
1
show tables;创建数据表
1 2 3 4 5 6 7 8 9
create table $table_name( $column_name $type null/not null [default $value] [auto_increment] [primary key], $column_name $type not null, [ index [index_name]($column_name, $column_name), primary key($column_name, $column_name), unique key [unique_name]($column_name, $column_name) ] )engine=InnoDB default charset=utf8
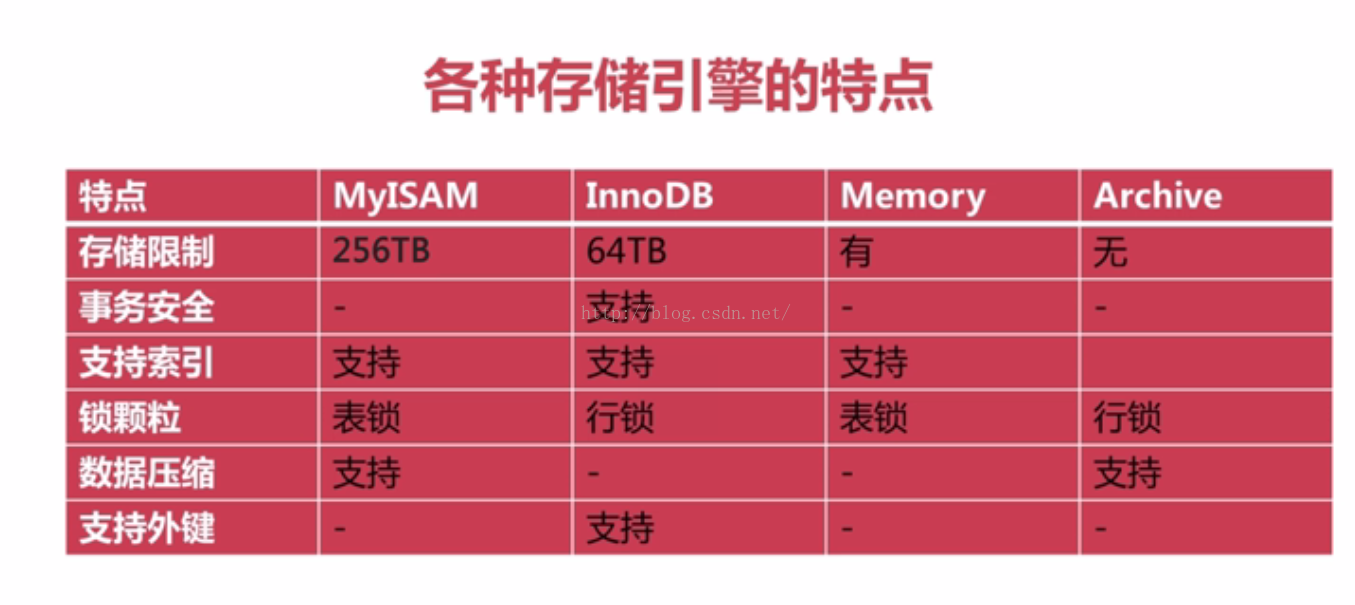
engine的区别是:![engine]()
删除表
1
drop table $table_name;
清空表
1 2 3 4
# 支持事务,可以回滚 delete from $table_name; # 即时生效,不支持事务,不能回滚 truncate table $table_name;
修改表
1 2 3 4 5 6 7 8 9 10 11 12
# 添加栏位 alter table $table_name add $column_name $type; #删除栏位 alter table $table_name drop column $column_name; # 修改栏位类型 alter table $table_name modify column $column_name $type; # 修改栏位名称+类型 alter table $table_name change $old_column_name $new_column_name $type; # 添加主键 alter table $table_name add primary key($column_name); # 删除主键 alter table $table_name drop primary key;
查看表结构
1
desc $table_name;
新增数据
1 2 3 4 5 6
# 插入一条 insert into $table_name($cloumn1,$column2,...) values($value1,$value2,...) # 插入多条 insert into $table_name($cloumn1,$column2,...) values($value1,$value2,...),($value1,$value2,...),... # 若插入包含了所有的栏位,insert可以忽略表栏位 insert into $table_name values($value1,$value2,...)
删除数据
1 2
delete from $table_name; delete from $table_name where ...;
更新数据
1
update $table_name set $column_name = $value where ...;
查询数据
1 2 3 4
select * from $table where ...; # 排序,限制 select * from $table where ... order by $column_name aes/desc limit $start_line, $length; select * from $table where ... limit $length [offset $start_line];
分组查询
1
select $column1, $column2, $column3,... from $table where ... group by $column1,$column2;
多表查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# left join, 以左表为主 select * from A left join B on A.id = B.id where ...; # right join, 以右表为主 select * from A right join B on A.id = B.id where ...; # 显示所有满足条件的数据 select * from A inner join B on A.id = B.id where ...; # 组合, 要求组合的栏位一致,默认去重 select $column1, $column2 from A union select $column3, $column4 from B; # 不去重,显示所有 select $column1, $column2 from A union all select $column3, $column4 from B;
栏位类型
bit[(m)]. 二进制, 默认m = 1tinyint[(m)] [unsigned] [zerofill]. 小整数。有符号:-128 ~ 127;无符号:0 ~ 255;
tinyint(1)表示布尔值。int[(m)] [unsigned] [zerofill]. 整数。bigint[(m)] [unsigned] [zerofill]. 大整数。decimal[(m[,d])] [unsigned] [zerofill]. m是数字个数, d是小数点后个数。float[(m, d)] [unsigned] [zerofill]. 单精度浮点数。double[(m, d)] [unsigned] [zerofill]. 双精度浮点数。char(m). 固定长度的字符串。需要注意的是,即使数据小于设定长度,也会占用m长度。varchar(m). 变长的字符串。text. 变长的大字符串。mediumtext.longtext.DATETIME. 不做改变,原值输入输出。TIMESTAMP. 它会把客户端插入的时间从当前时区转化为UTC进行存储;查询时,将其又转化为客户端当前时区时间。
执行顺序
mysql语句最多可以分为11步, 最先执行的是From, 最后执行的是Limit。每执行一步,都会生成一张虚拟表,并会作为下一步的数据源。
sql模板:
(8)
SELECT XXX (9) DISTINCT(XXX)
(1)
FROM table1
(3)
[INNER/LEFT/RIGHT] JOIN table2
(2)
ON xxx
(4)
WHERE xxx
(5)
GROUP BY xxx
(6)
WITH {CUBE|ROLLUP}
(7)
HAVING xxx
(10)
ORDER BY xxx
(11)
LIMIT xxx
按照顺序,具体分析每一阶段:
FROM. VT1
ON. VT2
JOIN.VT3
WHERE. 根据条件,过滤VT3的数据,生成VT4
GROUP BY. 对VT4进行分组,生成VT5
WITH. 根据
GROUP BY的分组,生成VT6WITH是与GROUP BY一起使用的,主要作用是同时对多个字段的不同组合,进行分组。支持两种:CUBE针对N列的
GROUP BY,CUBE需要进行2的N次方分组操作。如
GROUP BY c1, c2, c3 WITH CUBE,会生成以下分组数据:- c1
- c2
c3
- c1, c2
- c1, c3
- c2, c3
- c1, c2, c3
- (). 不分组, 表示对整张表聚合
ROLLUP针对N列的
GROUP BY,CUBE需要进行N次方分组操作。如
GROUP BY c1, c2, c3 WITH CUBE,会生成以下分组数据:c1
- c1, c2
- c1, c2, c3
- (). 不分组, 表示对整张表聚合
HAVING. 对VT6的数据, 进行过滤,生成VT7。
与
WHERE不同的是:1. 执行顺序 2.HAVING支持聚合函数,WHERE不支持。SELECT. 选择指定的列,生成VT8
DISTINCT.去重后,VT9
ORDER BY. 按照指定列进行排序,生成VT10
LIMIT.取出指定行记录,生成VT11,并返回。